CEDAR Project Descriptions
The current CEDAR projects are described below. We are starting with texts from well-known literary corpora that had a significant cultural impact and also have complex histories of revision, transmission, and translation, resulting in many textual variants and competing interpretations. Seven pilot projects are underway on the ancient Egyptian Book of the Dead, the Mesopotamian Epic of Gilgamesh, the Hebrew Bible (Old Testament), the Middle English poem Piers Plowman, Shakespeare’s The Taming of the Shrew, and Herman Melville’s first novel Typee: A Peep at Polynesian Life, plus a rather different project on indigenous pictographic sign systems of the Americas.
The reason for selecting radically different textual corpora of diverse dates and genres, which are studied by very different communities of scholars, is to show that, when properly designed at the right level of abstraction, the same underlying data structures and algorithms can be used to represent, visualize, and analyze any text from any period and culture. The same digital system can be used to display and compare textual variants and intra- and inter-textual relationships in accordance with the conventions of each field of scholarship.
Only by working collaboratively across our disciplinary boundaries to compare our texts and our scholarly practices can we identify the core features needed in a tool capable of constructing a digital critical edition suitable for use by expert scholars in any textual domain. No such tool currently exists but a common tool of this sort is badly needed because software for digital humanities is financially and institutionally sustainable only if it can be shared among many scholars to spread the cost of ongoing software maintenance, technical support, and documentation. The landscape of digital humanities is littered with defunct and discarded software created at great expense but tailored to the idiosyncrasies of a single project and thus incapable of being sustained over the long term. What is needed is a sophisticated computational platform that implements what Jerome McGann calls the “Turing Machine” of philology—the critical edition—and thus works for everyone while also respecting the conventions and nomenclature of each field.
The Hebrew Bible
The leader of this project is Jeffrey Stackert, Professor of Hebrew Bible in the University of Chicago, who also serves as a co-director (with Ellen MacKay) of the entire CEDAR initiative. The CEDAR Hebrew Bible collaborators are listed on the Project Teams page of this website.
Textual criticism of the Hebrew Bible has its roots in antiquity, when readers began to make comparisons between manuscripts and early translations of the biblical text, and it has continued in various forms ever since. New data available in the last half-century have fundamentally altered the state of the field: the discovery and publication of the Dead Sea Scrolls provided thousands of new readings and additional information for textual analysis. These manuscripts are especially valuable because they are more than a thousand years older than the oldest Hebrew Bible manuscripts we possessed previously. These exciting new data add to an already complex and unwieldy task that includes working with relevant textual variants in multiple languages (Hebrew, Aramaic, Greek, Syriac, Coptic, Latin); adjudicating fragmentary and sometimes badly damaged manuscripts; differentiating among different recensions or text-types within and across linguistic boundaries; and weighing diverse translation techniques and their implications for understanding the translation’s source text.
This research, which is fundamentally comparative, entails a deep mix of quantitative and qualitative modes of analysis. It calls for a digital solution—one that optimizes its thousands of moving parts and their exponentially larger number of possible combinations. Scholars are currently pursuing digital projects on the Greek Bible in Göttingen and on the Dead Sea Scrolls in both Haifa and Göttingen. There are also commercial software products available. Yet none of these provides a comprehensive presentation of the text of the Hebrew Bible with the capabilities needed to push research forward.
The OCHRE database platform used by CEDAR enables a new kind of digital critical edition of the Hebrew Bible because it allows multiple versions of the same text to be represented without error-prone duplication of information and without the unwieldy proliferation of manually constructed links among versions. This is a pressing need in biblical textual criticism, in particular, because there are hundreds of different and often conflicting manuscript witnesses for each biblical book. Some manuscripts are more complete than others (e.g., the medieval Leningrad Codex, dated 1008/9 CE), but none can be regarded as necessarily more faithful to the (now lost) original. The Hebrew Bible is known to us only from later copies and from translations into Greek, Latin, Syriac, etc., created centuries after the biblical texts were composed—not to mention the fact that the “original” version was often itself the product of a long process of revising and compiling earlier texts, especially in the Pentateuch.
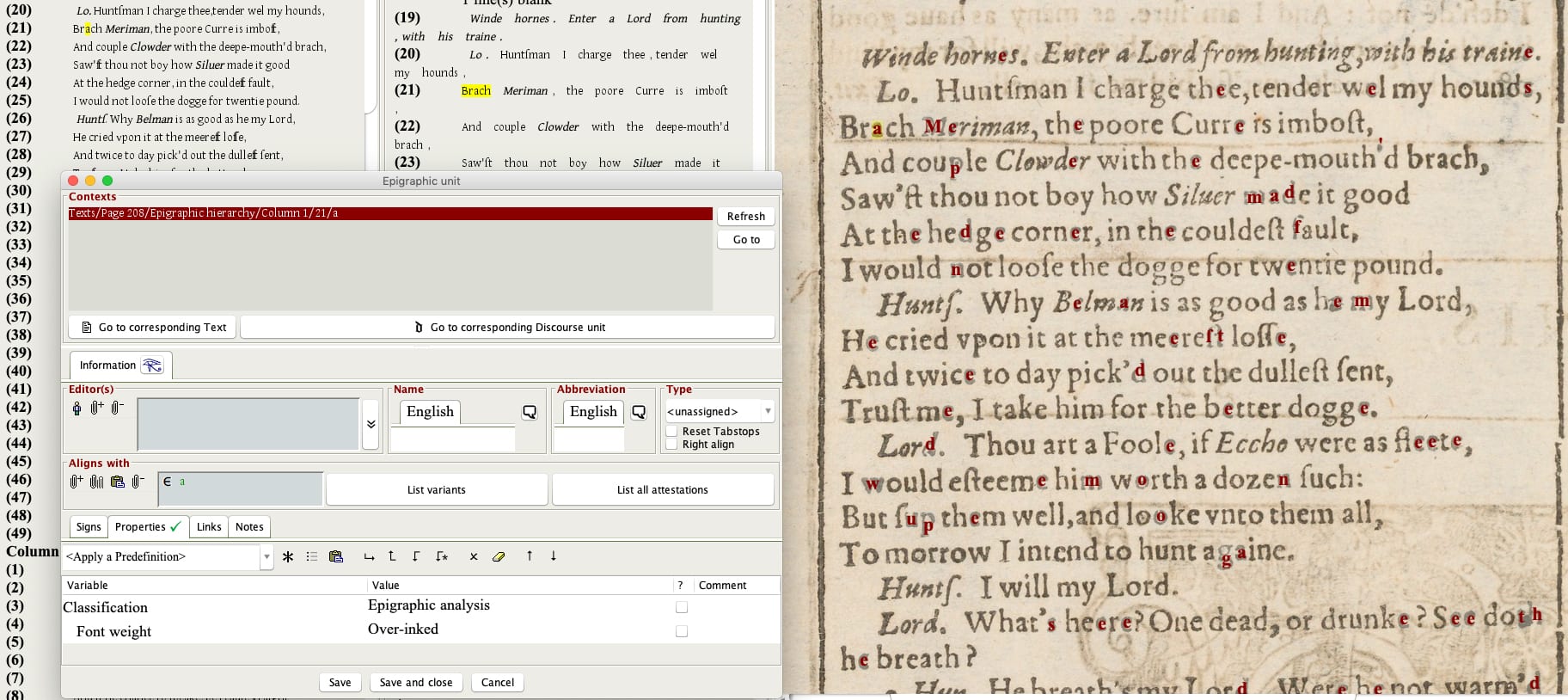
In Phase One of the CEDAR initiative (2017‒2021), progress was made by the Hebrew Bible team in digitizing selected manuscripts and working out the best method of representing digitally the individual epigraphic and discursive entities found within them and interlinking these atomized components. As of late 2021, the Bible team has worked with 354 manuscripts written in Hebrew, Greek, Latin, Coptic, Syriac, and Aramaic, entering 31 different chapters from eight different books of the Bible. A total of 312,762 epigraphic units (letters and vowel markings) and 72,621 discourse units have been atomized and interlinked as individually indexed database items from which various editorial readings and reconstructions of the presumed original version of the text and subsequent recensions may be generated.
Many of the software methods now used by other CEDAR projects were pioneered by the Hebrew Bible project. So far, the goal of this project has been to work out the concepts and procedures needed to construct online editions and iteratively test and refine the software used to implement those concepts and procedures. This task has been largely accomplished, so in Phase Two (2022‒2025) the Hebrew Bible team will focus on a larger-scale digitization of biblical manuscripts, representing more biblical books and chapters and making available in an open-access format more manuscripts of biblical texts than ever before, many of which have not previously been transcribed or have only been published in print. In Phase Two, the Hebrew Bible team will also work with the OCHRE computational staff to develop a Web app to present the contents of the database to scholars and students of various levels of sophistication.
Ultimately, the goal of this project is to apply the CEDAR tools to the entire Hebrew Bible, unleashing new possibilities for interpretation by making it much easier to visualize complex histories of textual transmission and revision and to create new editions based on alternative scholarly choices, with immediate access to all the empirical data contained in the manuscript witnesses, including high-resolution photographs of them. To this end, the CEDAR Hebrew Bible team has partnered with the Society of Biblical Literature’s series The Hebrew Bible: A Critical Edition (HBCE), which is edited by CEDAR collaborator Ronald Hendel of the University of California, Berkeley. Online editions viewed by scholars and students using a CEDAR app will be companions to the printed volumes in the HBCE.

The Epic of Gilgamesh
The OCHRE staff have worked for years with researchers in the Institute for the Study of Ancient Cultures (formerly the Oriental Institute) of the University of Chicago—a preeminent center of ancient studies—to digitize texts inscribed on clay tablets using the logosyllabic Mesopotamian cuneiform script, which was the first writing system ever invented. Tens of thousands of cuneiform tablets have been entered into the OCHRE database in exhaustive philological detail. Grammatical and lexical information has also been entered, enabling the automatic generation of OED-style philological dictionaries that show every spelling and every grammatical form of a lemma in all its textual contexts. These tools are available to all CEDAR projects and will be used, for example, in the Hebrew Bible project.
OCHRE’s capabilities far exceed those of other software used in cuneiform studies, which does not represent non-alphabetic signs directly but relies on Latin-alphabet transcriptions. An alphabetic transcription of a non-alphabetic text, even if it is a sign-by-sign transliteration, is wrongly treated in such software as a primary data structure rather than as a secondary way of displaying the text to modern readers. In OCHRE, by contrast, an alphabetic transcription is generated as needed from a more complete and accurate database representation of the actual written signs and tablets in full epigraphic detail.
Before the CEDAR initiative began in 2017, the cuneiform texts stored in the OCHRE database were limited to ephemeral administrative and epistolary texts rather than curated literary or legal texts that had been copied and re-copied as part of the Mesopotamian cultural tradition. The CEDAR Gilgamesh project provided an opportunity to work with a famous literary composition that was part of the cultural canon of ancient Mesopotamia. The Epic of Gilgamesh is an epic poem that had a long history of scribal transmission and interpretation in both the Sumerian and Akkadian (Babylonian and Assyrian) languages. The earliest extant versions in Sumerian date from ca. 2100 BCE and it was copied and revised for two millennia, resulting in many textual variants: orthographic, morphological, syntactical, and lexical. In its Standard Babylonian form, the Epic of Gilgamesh consists of about 3,000 lines divided among 12 tablets.
CEDAR methods developed for variants in biblical manuscripts apply equally well in this case, and the Gilgamesh team has made substantial progress as of late 2021, having entered into the database 16,502 epigraphic units and 13,822 discourse units from 88 tablets. When the project is completed, scholars and students will be able to use the CEDAR edition of Gilgamesh to compare and analyze all the manuscript witnesses of the Epic in both Sumerian and Babylonian and relate them to other cuneiform texts, which it is not now possible to do.
The Egyptian Book of the Dead
The leader of this project is Foy Scalf, Research Associate and Head of Research Archives in the Institute for the Study of Ancient Cultures (formerly the Oriental Institute) of the University of Chicago. He is an Egyptologist (UChicago Ph.D. 2014) who specializes in ancient Egyptian magic and funerary texts, including the Book of the Dead. The CEDAR Book of the Dead collaborators are listed on the Project Teams page of this website.
The ancient Egyptian Book of the Dead includes more than 190 magical spells intended to aid in the transition to the afterlife. As a clearly identifiable corpus, these spells appear in ca. 1700 BCE, but they often preserve material transmitted from earlier corpora, namely, the Coffin Texts and Pyramid Texts written several centuries earlier. Scholars can trace the transmission of these spells from the 24th century BCE to the second century CE. Spells that first appeared in the pyramid burial chamber of the Fifth Dynasty pharaoh Unas (ca. 2350 BCE), written in the hieroglyphic script, were still being copied in the Roman era in the cursive hieratic and demotic scripts. With more than 3,000 manuscripts discovered and published to date, the funerary-text tradition of the Egyptians, of which the Book of the Dead forms a primary part, is the best documented example of long-term textual transmission in the ancient world. However, despite the relative abundance of published manuscripts, little attention has been paid to the principles and mechanics of textual transmission in ancient Egypt, as opposed to narrow technical studies of individual texts or sub-classes of texts. A more general synthesis is urgently needed and would be of great value for scholars in other fields, such as biblical and classical studies, where the earliest manuscript traditions are far more fragmentary or non-existent. The Egyptian funerary corpus provides an exciting new area of text-critical study that raises fascinating questions about a very long-lived textual tradition and provides an excellent test case for CEDAR.
The CEDAR Book of the Dead team will attempt to answer the following questions: What are the primary characteristics of textual transmission in ancient Egypt? Can formal distinctions be made between texts that were directly copied (“reproductive” tradition) versus texts that were composed from memory or created ex nihilo (“productive” tradition)? How did the materiality of the texts affect their transmission? These questions will be addressed using selected texts from the 2,500-year span of the Egyptian funerary tradition. Texts will be chosen based on the number of manuscript witnesses, privileging texts with the longest attested history and most diverse modalities. The epigraphic and discursive contents of the manuscripts will be atomized and interlinked in the OCHRE database, which already supports the Egyptian hieroglyphic and hieratic scripts and has sophisticated mechanisms for dealing with non-alphabetic pictographic and logosyllabic texts, including vertical as well as horizontal (and bidirectional) orientations of writing and the ability to embed signs within signs. Software refinements may be needed, and the Book of the Dead team will work closely with the OCHRE staff to ensure that the computational tools meet the needs of Egyptologists.
Piers Plowman
This project is co-directed by Ian Cornelius, Associate Professor of English at Loyola University Chicago, and Timothy Stinson, Associate Professor of English at North Carolina State University, and is facilitated by Julie Orlemanski, Associate Professor of English at the University of Chicago, who specializes in texts from the late Middle Ages. Cornelius and Stinson are leading experts in medieval digital studies and specialists on the Middle English poem Piers Plowman. Stinson is co-founder and co-director of the Medieval Electronic Scholarly Alliance, director of the Society for Early English and Norse Electronic Texts, and co-director of the Piers Plowman Electronic Archive. Assisting them is Kashaf Qureshi, a Ph.D. student of English at the University of Chicago.
Piers Plowman is a long personification allegory and multilingual vision poem composed ca. 1365–1390 in English alliterative verse, Latin, and some French. The poem is transmitted in over fifty manuscript copies generally understood to represent three authorial versions, the lifework of a poet who used the name William Langland. The poem seems to have been an immediate success, read by lay and clerical possessioners in London and in the country, and evidently also known to some of the rural laborers and craftsmen who rose in rebellion in 1381. None of the surviving manuscript copies is an authorial holograph; all exhibit transmission errors characteristic of scribal copying. Strong demand for the poem drove repeated copying of it and quickly generated distinctive textual families; yet the lines of textual transmission are in part obscured by scribes who knew the poem in more than one version and created composite versions. A challenge for editors of the poem is accordingly to distinguish between variant readings introduced by scribes in the process of transmission and variant readings introduced by the poet in the process of revision. This work of textual curation and cultural restoration has been undertaken several times since the nineteenth century. The standard edition was published in three text volumes between 1965 and 1997, drawing on work begun in the 1930s. The text volumes were followed by a glossary and concordance. Since 2006 four volumes of commentary have appeared (of five projected).
The Athlone Piers Plowman, as this edition is known, is credited with introducing the principles of textual scholarship (pioneered by scholars of ancient literature and the Bible) into the field of medieval English literature and its accomplishment is widely recognized. Yet the edition also proved controversial. Controversy centered especially on the second of the Athlone text volumes, presenting the so-called B Version of Piers Plowman. In 1991 Hoyt N. Duggan convened a team of scholars with the aim of producing a new multi-version edition of Piers Plowman B, founded upon a full and open presentation of manuscript evidence necessarily suppressed within the printed volumes of the Athlone edition. Duggan’s insight was that electronic media released editors from an obligation to choose between documentary and critical poles of text-presentation: hyperlinks and style sheets would permit digital editions to honor both the archival documents and the literary works imperfectly transmitted in them. Between 2000 and 2011, the Piers Plowman Electronic Archive (PPEA) published documentary editions of seven manuscripts. Early editions were encoded in TEI-conformant SGML, accompanied by high-resolution digital images of the manuscripts, and distributed on CD-ROM. In 2014, these editions were converted to TEI-XML and re-published by PPEA. Throughout this period, PPEA managed a difficult balance between documentary-archival and editorial-reconstructive missions: Duggan’s team directed their documentary labors towards those copies necessary for the editorial reconstruction of the archetype of the B Version. Edited by John Burrow and Thorlac Turville-Petre and drawing upon three decades of labor by many hands, PPEA’s B-Version Archetype (Bx) was the culmination of this research trajectory. It is a major improvement over the Athlone edition of Piers Plowman B and supplies the best record of the text now available.
The Piers Plowman Electronic Archive is drawn into the CEDAR initiative by the power of the graph database model used in the OCHRE platform on which CEDAR rests. This supplies the technical means to make the individual editions fully interoperable and promises to release these editions from the confines of the TEI document structure. We are interested particularly in using the CEDAR tools to prototype a series of extensions to the edition of Bx: (1) collation of Bx against the principal critical editions of Piers Plowman B (the Athlone B Version and the edition by A.V.C. Schmidt); (2) inter-versional collation, producing a tagged set of Bx lines with cognates in the A and/or C Versions of the poem; (3) lexical and grammatical tagging of the text; and (4) analysis of the meter. The first three products would have immediate and general value to scholars of the poem; they would also add value to PPEA’s edition of Bx and bring new users to it. The metrical analysis would respond to an opportunity recognized by Turville-Petre in a 2013 essay (“The B Archetype of Piers Plowman as a Corpus for Metrical Analysis”). Moreover, unlike TEI, the OCHRE database permits these additional layers of markup to be developed, tested, and stored as atomized entities keyed to the published text of Bx yet not conflated with it. The edition by Burrow and Turville-Petre would retain its integrity while serving as a basis for further research. If, at a subsequent stage, other published and in-progress documentary editions of Piers Plowman manuscripts were ingested into OCHRE, the result would be a linked and queryable data set of great interest for the study of Middle English dialects and textual mouvaunce.
Beshrew Me! Shakespeare’s Taming of the Shrew and Early Modern Domestic Culture
The leader of this project is Ellen MacKay, Associate Professor of English at the University of Chicago, who also serves as a co-director (with Jeffrey Stackert) of the entire CEDAR initiative. The CEDAR Beshrew Me! collaborators are listed on the Project Teams page of this website.
In Phase One of the CEDAR initiative (2017–2021), the Shrew team entered 141 pages of text, yielding 217,798 epigraphic units and 170,550 discourse units. In Phase Two, in addition to completing the work of modeling the textual phenomena of The Taming of the Shrew, a major goal will be to link in images and descriptions of artifacts of early modern domestic culture, making accessible the material and visual world of the original audiences and illuminating the play itself.
One might ask why we need yet another digital project on Shakespeare. Digitizing Shakespeare has long been a thriving concern thanks to strong early initiatives to make his works more accessible. In the early days of hypertext and digital collection-building, digital imaging made rare, costly, and fragile Shakespeare books legible to students, researchers, and the wider public, but did not make them machine readable. Then, in 2013, the Folger Shakespeare Library rolled out its Digital Texts: carefully curated transcriptions of the plays in the TEI-XML format that are fully searchable, down to the punctuation mark, and machine readable for scholars working at scale. Consequently, stylometric analyses and topic-modelings of the plays have been plentiful, and these digital inquiries have yielded useful results, particularly in terms of the parameters of voice and genre—for instance, we now know that a hallmark of the Histories is their overreliance on the third person, and that the Comedies knit characters together via shared lines.
Shakespeare’s searchability and algorithmic manipulability have now become the standard to which the rest of English print aspires. Much current digital work on the English Renaissance involves cleaning up the rest of the 60,000 printed works digitized in Early English Books Online (EEBO) and transcribing them in the manner of the Folger’s Digital Texts. The resulting Early Print Library will help us to understand Shakespeare’s signature features in context, relative to the full panoply of the published writing of his age. It should be noted, however, that digital work on Shakespeare has prioritized the construction of a reliable, searchable, and machine-readable discursive record. The scope of that record has been expanding from Shakespeare, to the full range of early modern English drama (roughly 600 extant works), to all writing printed in England from the first days of the printing press to 1660. Within this landscape, the CEDAR tools open new and exciting lines of inquiry. The most important intervention is the collocation provided of the discursive text and the printed copy’s epigraphic features. All the bibliographic choices that make up the mise-en-page of a given play—the disposition the printer gives to dramatic concepts like act, scene, character, line, action, expression, or word—can now be raised for consideration alongside its textual language. Markings related to provenance, presentation (binding or display), and reader use (e.g., marginalia, underlining, manicules, doodles, folded corners, etc.) can be added to the mix.
In early modern textual studies, these features are attracting new attention as domains of significant theatrical and social argument. Beshrew Me! is a participant in that evolving discussion thanks to CEDAR’s innovative tools. The contents of early modern digital corpora typically include eclectic editorial composites derived from multiple copies and versions of a single text (a telling instance is the Folger Digital Texts’ Hamlet, which merges quarto and Folio expressions of the play, submerging their differences) or include simplified transcriptions of facsimile images of texts that leave unrecorded their lineation, marginalia, breaks, fonts, colorization, etc., and leave blank and uncorrected any damage. CEDAR, however, is designed to support a granular rendering of all the features of a particular copy, omitting nothing from the realm of computational analysis. A CEDAR edition is friendly to bibliographical study, taking account of all that EEBO and the Early Print Library leave out. It takes account of features that exceed the lexicon of descriptive bibliography, including material, aesthetic, and temporal properties of drama that have not yet been measured and offer new ways of classifying a given work, such as: (1) the volume of print on each page relative to the white space of each page, (2) the size of each speaking part (the number of syllables spoken by each identified or identifiable role); (3) the size of each character’s non-speaking part (the number of syllables he or she does not speak among those spoken while he or she is onstage); (4) the relative clearness or opacity of a given dramatic unit (line, character, scene, stage direction) in terms of compositor error, format conventionality, etc. These points of information yield new forms and figures to think with, including “light” plays versus “dark” ones, unseen characters versus unheard ones, wide-framed texts that orchestrate annotated readings versus barely bounded ones that crowd out readers’ thoughts.
Finally, CEDAR’s most conspicuous contribution to Digital Shakespeare Studies involves the choice of The Taming of the Shrew as the place to start. In a platform designed to bring out textual variants, it is an intriguing choice. It exists in Folio in a clean and unproblematic state, but it bears some as-yet-untraced affiliation to an anonymous play titled The Taming of A Shrew that seems to have preceded it on stage, and it is succeeded by a Fletcher play, The Tamer Tamed, that spins the tale in the opposite direction. Whereas variants in Shakespeare texts have historically been opportunities to make judgments about authorship on the basis of poetic quality (the “bad quartos” are illustrative of this habit), the versions of Shrew show Shakespeare to be merely one among many early modern sites of expression for the dissemination of a folkloric topos of Shrew and Shrew-tamer. By digesting his play within a corpus of works that employ similar characters, tropes, sentiments, jokes, gestures, and gimmicks, we avoid consolidating Shakespeare’s canonicity as the paragon of his age.
This de-centering of the author from Shakespeare’s digital study excises the figure that Wimsatt and Beardsley warned long ago “is neither available nor desirable as a standard” for assessing and interpreting literary art. Instead, Beshrew Me! avails itself of the playwright’s canonicity, and the consequent careful preservation of his corpus, as a means to recover the hierarchical practices of domestic culture. Currently in development is a CEDAR presentation of The Taming of the Shrew that illustrate the play’s construction out of Common Parlance (proverbs and other non-proprietary sayings), Scriptive Objects (properties that serve as instruments and advertisements for domestic governance) and Gestural Iconography (actions with strong meanings in the long history of oppression and resistance, like placing a hand beneath a boot). By reversing the usual priority of (authorial) text and (cultural) context, the project makes visible and addressable some of the everyday machinations of structural inequality. CEDAR provides the digital architecture for an edition that can take account of the smallest traces of a book’s particularity—like the hole left by a binder’s needle—as well as the broadest measure of a work’s relation to the lifeworld in which it was produced.
Indigenous American Sign Systems
The leader of this project is Edgar Garcia, Associate Professor of English at the University of Chicago. He is a poet and scholar of the hemispheric cultures of the Americas and author of Signs of the Americas: A Poetics of Pictography, Hieroglyphs, and Khipu (2020). Assisting him will be Julia Marsan, a Ph.D. student of Comparative Literature. The CEDAR Indigenous Sign Systems collaborators are listed on the Project Teams page of this website.
The problem of representing indigenous American literatures is a longstanding one, entangled with centuries of alphabetic chauvinism. The CEDAR tools will enable studies of indigenous non-alphabetic literatures to shift away from their content—and the cultural bias that makes them into a particular kind of content—to a consideration of their form, expression, and even interpretability as non-alphabetic works. Oral and pictographic works should be represented in a way that does not prioritize the alphabet or even writing but allows semiotic elements to find relations to one other in accordance with the cultural system that shaped those works. This will be done in conversation with the CEDAR projects that deal with non-alphabetic literatures from ancient Egypt and Mesopotamia. The CEDAR Indigenous Sign Systems project will begin with a few sites of colonial inscription and study the relation of contemporary indigenous literatures to these first instances of inscription. The colonial moment of inscription is key because in such moments of remediation the problematics and possibilities of indigenous literary modes are highlighted. The mutually animating qualities of alphabetic, pictographic, and oral poetries are never so clear as when they vie for a reader’s attention in a text.
Specifically, we will start with the touchstone visual grammars of colonial language study: Diego de Landa’s transcription of Mayan hieroglyphs in 1566 (in Relación de las Cosas de Yucatán) and George Copway’s (a.k.a. Kah-ge-ga-gah-bowh’s) transcription of Ojibwe pictographs in 1850 (in Traditional History and Characteristic Sketches of the Ojibway Nation). Although these works are contextually and formally distinct, both have had a seminal relation to the study of the hieroglyphic and pictographic scripts of the Americas. They have grounded the study of semiotics in the Americas, seeding and complicating critical and creative works by indigenous and non-indigenous writers for centuries. The Indigenous American Sign Systems team will aim not only to represent the complex relation between script, sound, and image in these visual grammars, but also to ramify some of the social history of their various remediations and adaptations in later generations. This double layer—within the text and outside it, specific to it and resonating beyond it in later writings and works—will inform how we then enlarge the project to include other texts, script traditions, languages, and cultural contexts (e.g., Mexica pictography and Lakota ledger art).
The Works of Herman Melville
The leader of this project is John Bryant, Professor Emeritus of English at Hofstra University, a leading Melville scholar and Director of the Melville Electronic Library. Collaborators include Wyn Kelley, Senior Lecturer in Literature at the Massachusetts Institute of Technology, and Christopher Ohge, Senior Lecturer in Digital Approaches to Literature at the University of London. Eric Slauter, Associate Professor of English at the University of Chicago, serves in an advisory capacity. Brion Drake, a Ph.D. student in English, is the student assistant.
The CEDAR Melville project builds on John Bryant’s work on “the fluid text” and the methods he and his collaborators have developed for digital critical editions of Melville’s works (see Bryant’s The Fluid Text: A Theory of Revision and Editing for Book and Screen; University of Michigan Press, 2002). Fluid texts exist in multiple versions, due to authorial, editorial, or adaptive revision. They evolve physically, in revisions found in manuscript and print; our readings of these versions are modified by translation and adaptation in other media (illustration, stage, film, music, art). Traditional scholarly editing, which aims to represent the editors’ conception of a writer’s final intentions, generally relegates the evidence of textual fluidity to the abbreviated and recondite textual apparatus, displayed at the foot of a page or consigned to the back of the edition. Fluid-text editing, however, aims to represent the shifting intentions of authors, editors, and adaptors through a sequence of versions and uses digital technology to enable readers to identify revisions, navigate from one version to the next, and provide revision annotation in the form of reasonably determined “revision sequences” and interpretive “revision narratives,” thus making visible the unseen steps of revision.
But where shall we start? We tend to associate Herman Melville (1819‒1891) with Moby-Dick (1851). After all, this masterpiece is a widely acclaimed classic. But what justifies this iconic status? Why does the novel endure? What is its deeper appeal? How did Melville’s talent evolve? These questions might as easily be asked of Melville’s less-familiar writings, which have at their core hidden traumas and an abiding empathy for the dispossessed peoples who suffer them. Melville invented a word for such human beings: he called them “isolatoes.” In his fiction, they include not only god-hungry Ahab, outcast Ishmael, and the “crazy-witty” Black cabin boy Pip in Moby-Dick but also an array of alienated, abused, disabled, diseased, and under-class characters: exploited indigenous islanders (in Typee), mutinous sailors (in Omoo and White-Jacket), father-angry adolescents (in Redburn and Pierre), office workers (in “Bartleby”), factory women (in “Tartarus of Maids”), abandoned women (in “The Piazza” and “Chola Widow”), and the falsely accused handsome sailor and his sexually repressed accuser (in Billy Budd), to mention only a few. Granted, getting at the meaning of the trauma of dispossession in Melville’s work is a task we might assign to biographers and critics, but editors play a crucial role in giving readers access to the full range of versions and revisions—the fluid texts of a writer’s work—that in their evolutions also embody such meanings.
How Melville’s empathy for the dispossessed evolved as his talents as a writer grew can be traced in his revision processes. That said, the obstacle to such tracking is that, while sites of revision on a page may seem visible, the steps in making the changes are inherently invisible. We might try to read deletions and insertions scribbled on Melville’s often illegible manuscript leaves or discern changes through the careful comparison of print versions. But even with that data before us, we must still consider how a sequence of revisions unfolds, and we must argue a case for that sequencing and what it might mean. Arguments about revision cannot happen unless revisions, from version to version, are made visible, and this visualization is enabled by digital tools. The Melville Electronic Library’s editions of Moby-Dick, Melville’s collection of Civil War poems Battle-Pieces, and his last prose work Billy Budd model this approach to editing the versions of three different kinds of fluid texts.
The CEDAR Melville team will build on this editorial work with Melville’s first book Typee: A Peep at Polynesian Life (1846). Based on his youthful exploits in the Marquesas Islands of the South Pacific, Typee is—in terms of its surviving manuscript and several variant print editions—the most complicated of Melville’s fluid texts. Three of its 34 chapters exist as an early and heavily revised working-draft manuscript whose final text was later heavily revised for the first British edition. The subsequent American and American Revised editions were each significantly expurgated because of Typee’s sexual, religious, and political content. Our initial focus will be on representing, tracking, and analyzing the processes of authorial and editorial revision in manuscript and print that comprise Melville’s first fluid text. The textual revisions and various reconstructions of the revision sequences will be stored in the OCHRE database with editorial annotations of the critical choices being made—what Bryant has called “revision narratives.” The database can store and compare multiple revision sequences and their corresponding revision narratives created by, and attributed to, different scholars; and it can do so efficiently, without error-prone duplication of data, while linking each editorial intervention to the varying versions of the text that supply the content pool of variants stored in the OCHRE database.
After Typee, the CEDAR Melville team will move on to “Benito Cereno,” a novella about a slave revolt on a Spanish ship, first published in three installments in Putnam’s Monthly in 1855 and then reprinted with revisions in Melville’s short-story collection titled Piazza Tales. Typee and “Benito Cereno,” taken as bookends for Melville’s most productive period as a fiction writer, offer remarkable evidence of Melville’s shifting narratorial approaches to the political and historical traumas of racial, colonial, and cultural conflict. Both works passed through multiple and different kinds of versions, in ways to be revealed to readers by the Melville Electronic Library’s new CEDAR editions, opening new avenues of interpretation for Melville’s works as fluid texts.